

データサイエンスは、現代社会でますます重要性が増している分野です。
ビッグデータの時代において、データを分析し、有用な情報を引き出すことが求められています。そのため、データサイエンティストは、企業や研究機関、政府機関などで必要不可欠な存在となっています。
これまで私はデータサイエンスを学ぶために、キカガクの「データサイエンス入門コース」「データサイエンス実践コース」を受講し、その体験談をこちらで紹介してきました。
今回は実際にどれだけのスキルが身についたのか確認するためにデータ分析に挑戦してみましたので、これからデータサイエンティストを目指される方は是非参考にしてみてください。
使用したデータ
今回はSIGNATEの「民泊サービスの宿泊価格予測」の学習用データを用いました。本データはサンプルサイズが55583、カラム数(変数)が29です。また、分析前に以下の前処理を実施しました。
- カテゴリカル変数は削除(簡単のため)
- 欠損値が多い「review_scores_rating」は削除
- 「bathrooms」「bedrooms」「beds」の欠損値は平均値で補完
分析には上記前処理を施したサンプルサイズ55583、カラム数(変数)8のデータを用いました。データ内の各項目は以下の通りです。
| 変数 | 説明 |
|---|---|
| accommodates | 収容可能人数 |
| bathrooms | 風呂数 |
| bedrooms | ベッドルーム数 |
| beds | ベッド数 |
| latitude | 緯度 |
| longitude | 経度 |
| number_of_reviews | レビュー数 |
| y | 宿泊価格 |
今回、分析全体の目的変数としてy(宿泊価格)を使用し、その他の変数は説明変数として扱いました。
背景と目的
データ分析を実施した背景と目的は以下のように定めました。
Aさんは近々民泊経営を始めようとしており、民泊サービスの物件データを参考に妥当な宿泊価格を決めようとしていた。しかし、物件データには複数の項目があり、どれに着目すべきか不明であった。そこで宿泊価格に寄与している項目を見つけ出し、宿泊価格の参考にすることを分析の目的とした。
分析の結果
- 宿泊施設の大きさに関わる「accommodates」「bathrooms」「bedrooms」が宿泊価格への影響が大きい
- 特に「accommodates」は最も宿泊価格に影響している
- 大きな宿泊施設の場合、「bathrooms」「bedrooms」も宿泊価格に影響する
詳細
基本統計量
まずはデータの確認のため、各変数の基本統計量を確認しました。y(宿泊価格)は1~1999とかなり大きく振れています。ただし、中央値は111ですので、一部料金の高い宿泊施設が存在しているだけのようです。
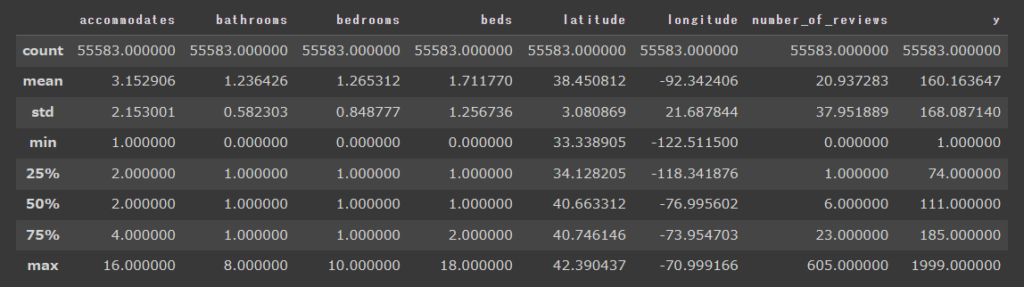
慣れてくるとデータの可視化を行わなくても、データの分布や傾向を一目で理解することが可能になります
相関解析(ヒートマップ)
次に各変数間の相関関係をヒートマップを用いて確認しました。ヒートマップは各変数間の相関係数を可視化することが可能です。
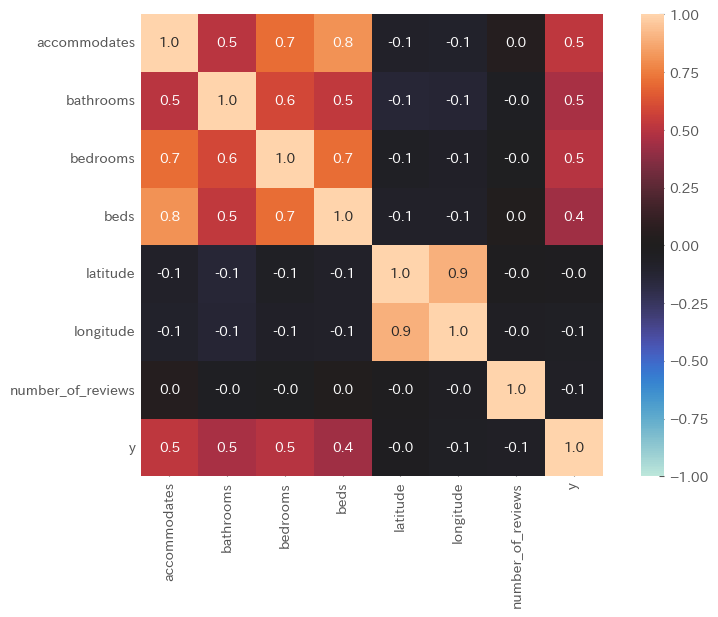
結果、「accommodates」「bathrooms」「bedrooms」「beds」はy(宿泊価格)と正の相関が認められました。また、無相関検定よりどれもp 値が有意水準 5% を下回ったため、母集団についても相関があると考えられます。
また、「accommodates」と「bathrooms」と「bedrooms」と「beds」、及び「latitude」と「longitude」は各変数間で強く相関していることもわかりました。
ヒートマップは変数間の相関を簡単に確認できるし、実装も楽ちんなのでとても便利!
要因解析(重回帰分析)
次にy(宿泊価格)に対する各変数の影響度合いを解析するために重回帰分析を実施しました。重回帰分析の偏回帰係数は、用いている複数の説明変数を考慮した上での目的変数に対するそれぞれの影響度合いを算出することができます。
重回帰分析
重回帰分析の結果を以下に示します。
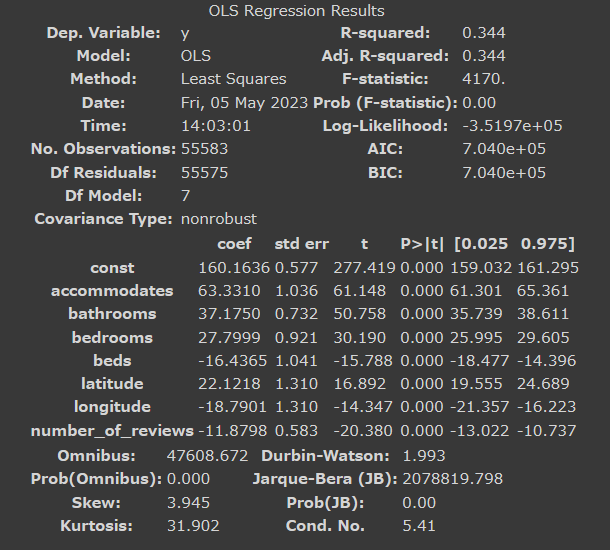
【結果】
自由度調整済み決定係数(Adj. R-squared)は0.344と低く、モデルは元データをうまく表現できているとは言えませんでした。
y(宿泊価格)への影響度
次に以下基準を満たす項目を抽出し、y(宿泊価格)への影響度の大きい項目をソートしました。
- t 値の絶対値が 2 以上
- P 値が 5% 以下
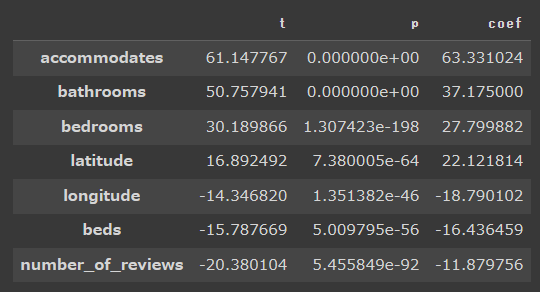
【結果】
「accommodates」「bathrooms」「bedrooms」の影響度が高く、これは相関解析の結果と一致しています。ただし、各変数間の相関係数が高い場合、偏回帰係数が不安定化することが知られており、さらに自由度調整済み決定係数が低いことも考慮すると、本結果は信頼性が高いとは言えません。
変数間の相関が強い場合はPLS(部分的最小二乗法)を使用してみよう
主成分分析
次に次元削減を行うため主成分分析を実施しました。主成分分析は可能な限り元データの情報を保持したまま、低次元データ(主成分)に変換する手法であり、可視化によりデータの全体像を直観的に把握できるメリットがあります。また、変数間の相関が強い場合にも有効です。
主成分の解釈
今回は7つの説明変数を2つの主成分に変換しました。各主成分がどのような意味を持つ変数であるか解釈するため、主成分負荷量を使用しました。主成分負荷量は各主成分に対して元の変数がどれくらいの影響しているかを表現した値です。今回はヒートマップを使用してこれを可視化しました。
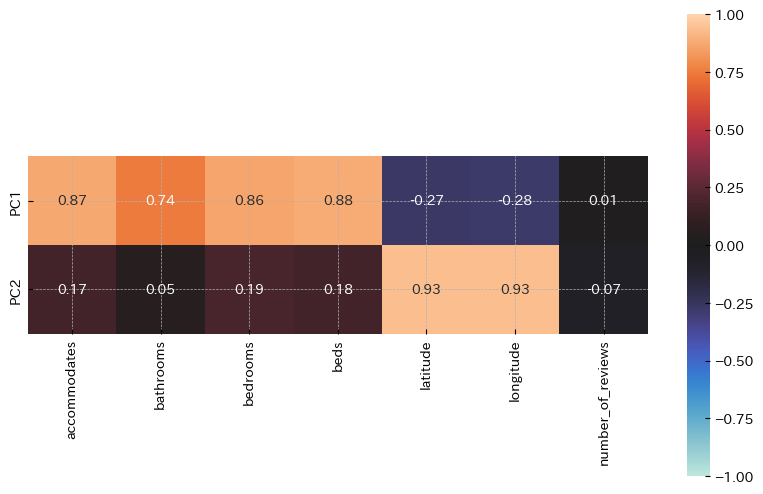
【結果】
第一主成分(PC1)は「accommodates」「bathrooms」「bedrooms」「beds」の影響が強く、「施設の大きさ」を表していると解釈しました。
第二主成分(PC2)は「latitude」「longitude」の影響が強く、「施設の立地」を表していると解釈しました。
各主成分の可視化
次に第一主成分と第二主成分の主成分得点(元データから求めた主成分の数値)をプロットしました。尚、紫色から黄色になるにつれてy(宿泊価格)が増加していることを表しています。
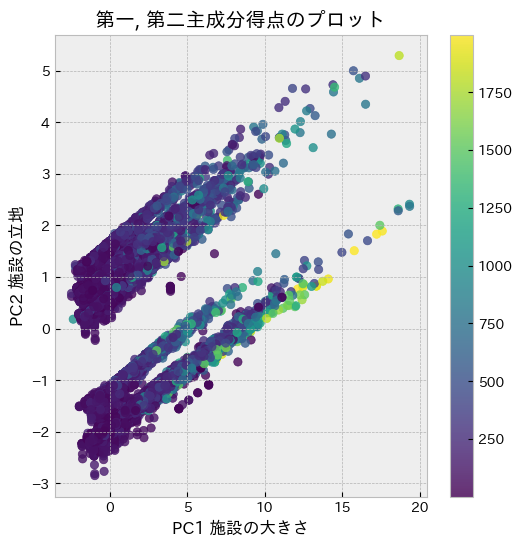
【結果】
第一主成分である「施設の大きさ」が大きくなるにつれてy(宿泊価格)が増加する傾向がみられました。
一方で第二主成分である「施設の立地」とy(宿泊価格)には明確な相関は見られませんでした。
可視化できるとデータを直感的に理解したり、他の人にデータを説明したりする際に便利!
クラスタリング
次にデータのグループ分けを行うためにクラスタリングを実施しました。クラスタリングは主成分分析と同様にデータの特徴などを踏まえるために使用されるデータマイニングの手法ですが、主成分分析とは違う観点からデータを捉えることができます。
クラスタの解釈
クラスタの数はエルボー法を使用して3としました。変数毎に各クラスタの平均値を棒グラフで可視化し、各クラスタの意味合いを考察しました。
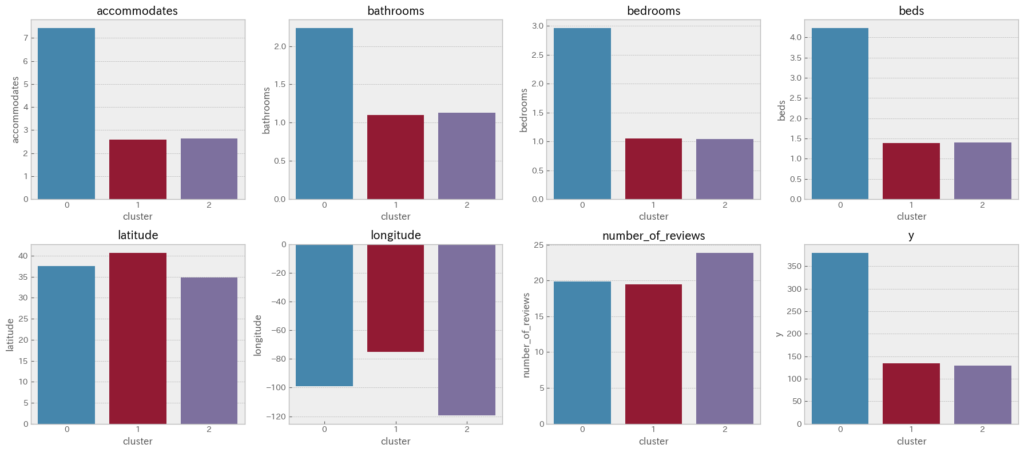
【結果】
クラスタ0は他のクラスタと比較して「accommodates」「bathrooms」「bedrooms」「beds」が高いため、「大きい施設」のクラスタと定義しました。
クラスタ1はクラスタ0よりも「accommodates」「bathrooms」「bedrooms」「beds」が低く、他のクラスタと比較して「latitude」「longitude」が高いため、「高緯度・高経度の小さい施設」のクラスタと定義しました。
クラスタ2はクラスタ0よりも「accommodates」「bathrooms」「bedrooms」「beds」が低く、他のクラスタと比較して「latitude」「longitude」が低いため、「低緯度・低経度の小さい施設」のクラスタと定義しました。
クラスタリングと主成分分析の組み合わせ
主成分分析とクラスタリングの結果を合わせることにより、各クラスタの解釈を視覚的に確認しました。
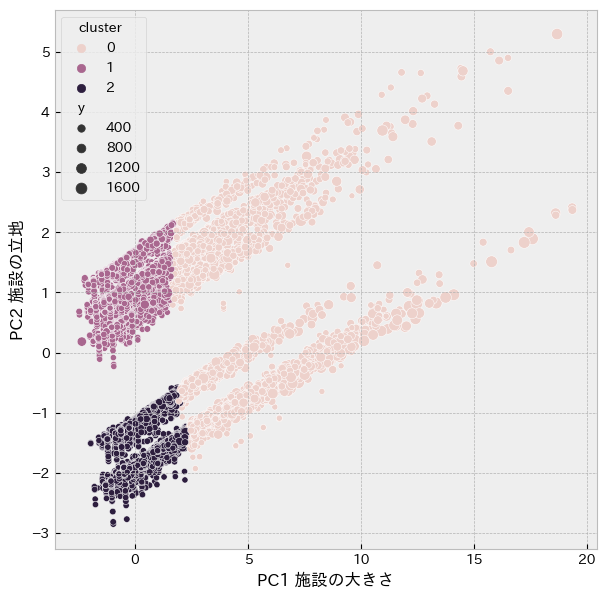
【結果】
各クラスタは「施設の大きさ」と「施設の立地」で明確にグループ分けされ、クラスタの解釈が正しいことを確認できました。
各クラスタ毎における各変数と宿泊価格(y)の分布
各クラスタ毎で各変数とy(宿泊価格)の分布を確認するために箱ひげ図を用いました。
accommodatesとy(宿泊価格)
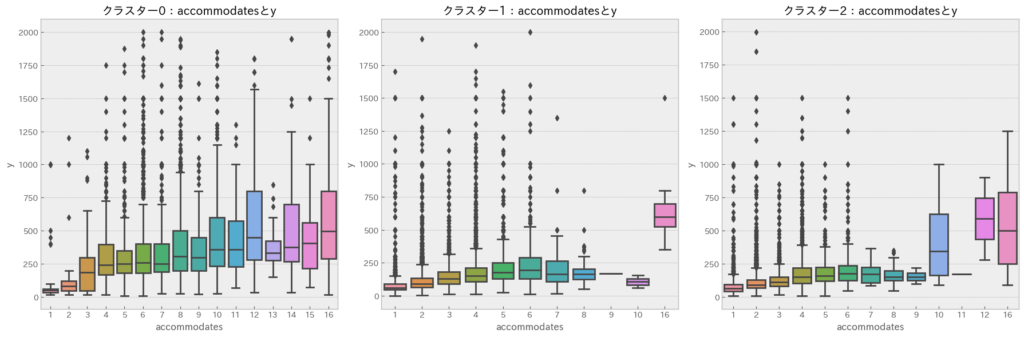
どのクラスタも「accomodates」が増加するにつれてy(宿泊価格)が増加する傾向が見られます。したがって、「accomodates」は宿泊価格を決定するうえで最も着目すべき項目であると考えられます。
bathroomsとy(宿泊価格)
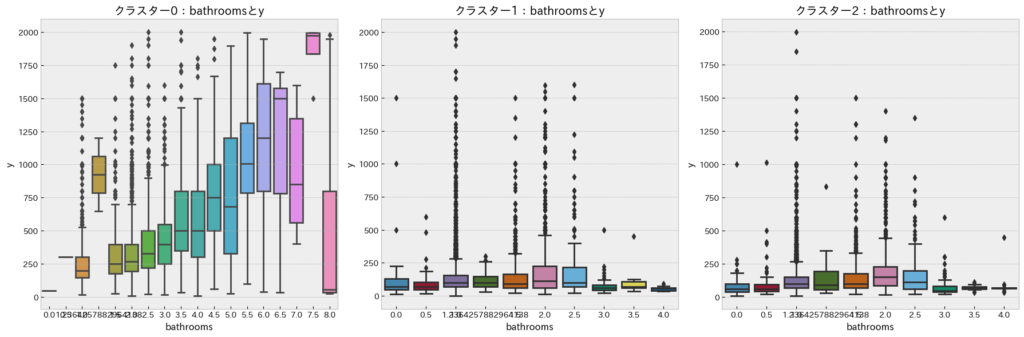
クラスタ0の「大きい施設」では「bathrooms」が増加するにつれてy(宿泊価格)が増加する傾向が見られます。一方でクラスタ1、2の「小さい施設」では上記傾向はみられません。したがって、「大きい施設」の場合は宿泊価格を決定する上で「bathrooms」にも着目すべきであると考えられます。
bedroomsとy(宿泊価格)
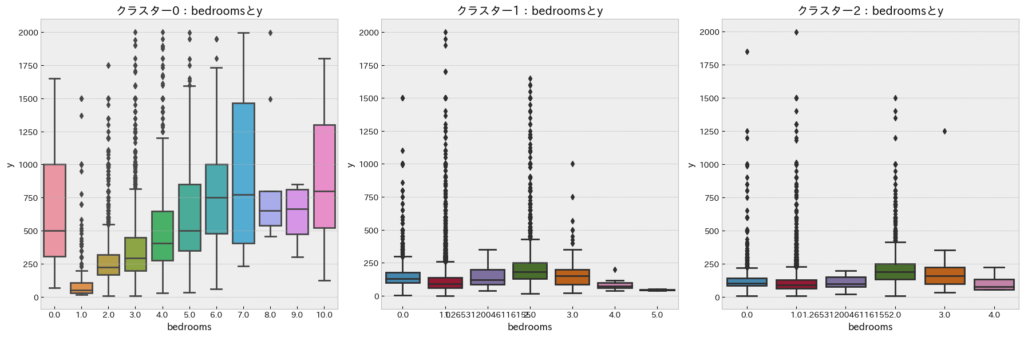
「bathrooms」と同様の傾向です。したがって、「大きい施設」の場合は宿泊価格を決定する上で「bedrooms」にも着目すべきであると考えられます。
bedsとy(宿泊価格)
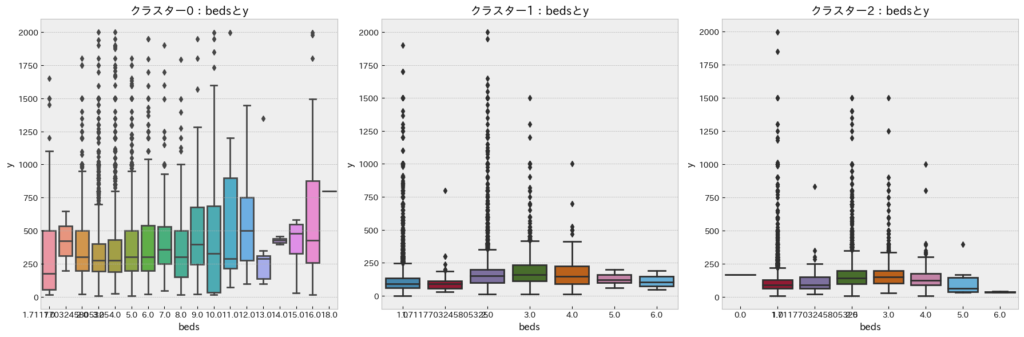
クラスタ0の「大きい施設」では「beds」が増加するにつれてy(宿泊価格)が極わずかに増加する傾向が見られますが、全体的にy(宿泊価格)への影響は少ないようです。したがって、「beds」は宿泊価格を決定する上で、重要性はあまり高くないと考えられます。
グループに分類することで、複数のターゲット層の傾向を掴むことができるので、それぞれの層に異なった施策を打つことができる可能性もあります!
データ分析で詰まったポイント
実データを用いたデータ分析を行う上でいくつか詰まってしまうことがありました。参考までにそのポイントを挙げたいと思います。
変数の数
説明変数があまりにも多すぎるデータは多変量解析で傾向を捉えることが難しいです。特に主成分分析の各主成分やクラスタリングの各クラスタの解釈は非常に難解になります。
そこで最初はある程度変数を絞って、全体傾向を掴んでから、少しずつ変数を追加していくのが良いのではないかと思いました。例えば、相関解析である程度相関係数の強い変数から初めて、少しずつ増やしていく方法等が考えられます。
ちなみに今回はある程度数値データのみで傾向が取れそうだったので、下記コードでカテゴリカル変数を削除しました。さらに深く分析する場合はカテゴリカル変数を加えて分析するのが良さそうです。
df = df.select_dtypes(include=’number’)
欠損値の処理
「データサイエンス実践コース」ではきれいに加工されたテーブルデータを用いているので、特に前処理の必要はありませんでしたが、実際のデータはほとんどの場合、加工されていないデータを使用すると思います。
そのようなデータには何も入力されていないセルが存在し、これを欠損値と呼びます。欠損値があると重回帰分析などを実施することができず、これを下記コードで処理する必要がありました。
欠損値の確認:df.isnull().sum()
欠損値のある列の除去:df = df.drop(“review_scores_rating”, axis=1)
欠損値を平均値で補完:df = df.fillna({“bathrooms” :df[“bathrooms”].mean()})
ちなみに実際のデータには3、三、Ⅲのように同じ意味でも表記が異なる「表記ゆれ」も存在する場合もあり、これも確認・対処しなければいけません
データの取得とデータベースへの格納
実業務でデータ分析を実施しようと考えた際に、分析目的に沿ったデータがない、またはデータサイズが小さいという問題が起こりました。データ分析ではデータ数が多いほど精度が高い分析ができるため、目的に沿ったデータの取得とデータベースへの格納を自動化する技術が必要だと考えています。
例えばWebスクレイピングやAPIを利用したデータの取得等が考えられますが、今後はこれら技術についても学んでいこうと思っています。
個人的には目的に沿ったデータ取得が一番大変
特に目的変数に影響する説明変数を抜けなく取得できるかがポイント!
感想とアドバイス
今回、キカガクの「データサイエンス入門コース」「データサイエンス実践コース」で学んだ技術を実際のデータに適用することで、学習内容をより身につけることができたと思います。
また実際にデータ分析を実施する中で、いくつかの課題にも気づくことができました。今後は目的に沿ったデータの取得とデータベースへの格納を自動化する技術について調査を行い、このブログで共有していけたらと思います。
これからデータサイエンティストを目指される方にアドバイスですが、学んだ内容はとにかく実際に使用してみましょう!人間は時間が経てば経つほど、忘れてしまう生き物です。今回ご紹介したSIGNATEのデータセットでも良いかと思いますが、まずは学んだ技術を使ってみて、色々と考えたり、悩んだりしてみてください。
初めは難しいと感じるかと思いますが、学んだ内容が段々と自分のものになっていくことを体感できると思います。
それではこれからも一緒にデータサイエンスの勉強を頑張りましょう!

![]()


コメント