

E資格問題にチャレンジ!本日のお題は「YOLO」
問題
[問題]
以下のうち、YOLOについて誤っているものはどれか。
(A) 画像をグリッドセルに分割し、各セルは複数のバウンディングボックスと信頼スコア、および各クラスに対する条件付きクラス確率を出力する。
(B) 信頼度の高いバウンディングボックスを基準にNon-Maximum Suppressionにより選別する。
(C) YOLOは画像全体を一度に見るため、高速な物体検出が可能であり、複数のスケールの特徴マップを使用することで特に小さな物体検出に優れる。
(D) YOLOはエンドツーエンドのネットワークアーキテクチャを使用し、物体検出を1つの単一のニューラルネットワークで処理することができる。
答え
C
解説
YOLO(You Only Look Once)は、リアルタイム物体検出アルゴリズムであり、コンピュータビジョンの分野で広く使用されています。YOLOは、画像またはビデオフレーム内の物体を検出し、その位置とクラスラベルを推定します。
YOLOはR-CNNのように候補領域検出を行わない代わりに、入力画像をS*Sのグリッドセルに分割します(論文ではS=7に設定)。
つぎに各グリッドセルはC個のクラスに対する条件付きクラス確率Pを予測します(論文ではC= 20)。
さらに各グリッドセルは、B個のバウンディングボックスを持ち(論文ではB=2に設定)、それらのボックスの信頼スコアを予測します。信頼スコアは、ボックスに物体(Objects)が含まれているかの確率を示すものです。各バウンディングボックスは、座標値(x、y、w、h)と、信頼スコアの5つの予測で構成されています。したがって、(A)は正しい記述です。
その後、バウンディングボックスの信頼スコアと条件付きクラス確率を掛け、バウンディングボックス毎のクラスに対する信頼スコアを得ます。この信頼スコアに基づき、信頼度の高いバウンディングボックスを基準にNMS(Non-Maximum Suppression)という手法で選別します。NMSは、IoU値が大きい(重なり度合いの高い)領域をしきい値で抑制します。したがって、(B)は正しい記述です。
従来の物体検出手法では、画像内の物体を検出するために複数のステップ(領域提案、特徴抽出、クラス分類)が必要でした。しかし、YOLOはエンドツーエンドのネットワークアーキテクチャを使用しており、物体検出を1つの単一のニューラルネットワークで処理することができます。したがって、(D)は正しい記述です。
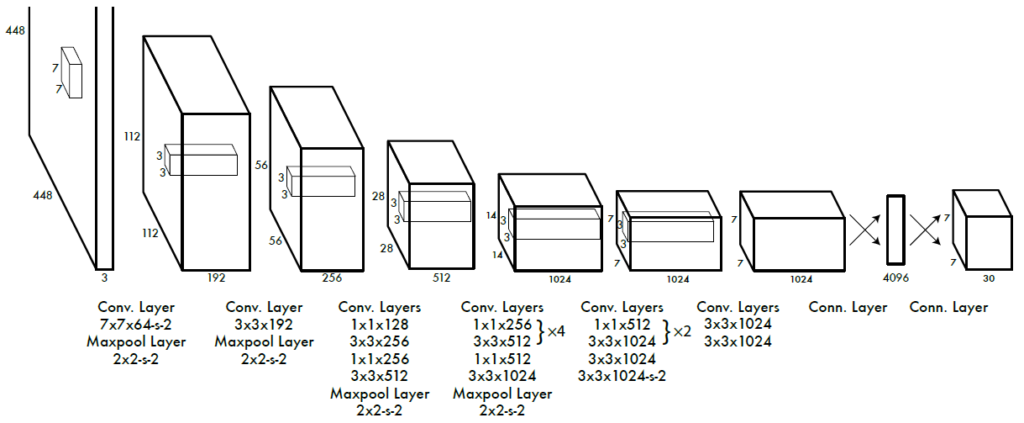
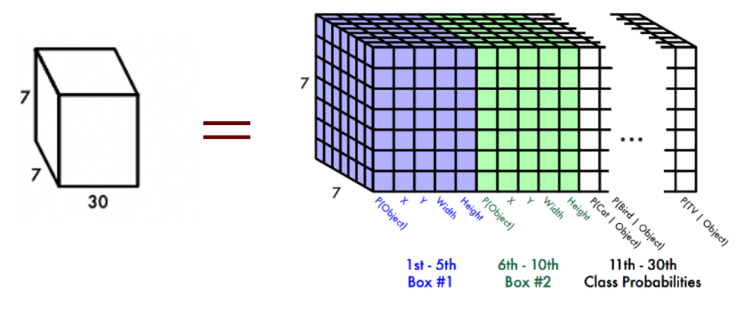
YOLOのグリッドセルベースのアプローチでは、画像を固定サイズのグリッドに分割し、各セルで物体の存在を予測します。しかし、グリッドセルは物体が小さい場合には十分な解像度を提供できず、小さな物体検出が困難であることがデメリットとして挙げられます。したがって、(C)は誤った記述です。
しかし、YOLOは、多くの応用分野で利用されており、自動運転、監視カメラ、画像認識などの領域で効果的に使用されています。その高速な物体検出能力とリアルタイム性は、リソース制約のある環境やリアルタイムアプリケーションに特に有益です。




コメント